Claude Sonnet 4.7 vs GPT-5.5 for Salesforce Agents

If you are building Salesforce agents in May 2026, the model choice is no longer “which model is smartest?” That is the wrong question.
The better question is: which model fails in the least expensive way for this Salesforce workflow?
For Salesforce agents, I care about five things:
- Can the model follow business policy without inventing shortcuts?
- Can it call tools cleanly and recover when Salesforce returns messy data?
- Can it reason over CRM context without leaking sensitive fields?
- Can it produce deterministic enough output for enterprise audit?
- Can I afford the latency and cost at real support or sales volume?
This is where the claude sonnet 4.7 vs gpt 5.5 salesforce comparison gets practical. I use both. I do not treat either as a religion.
Here’s the unpopular take: for many Salesforce agent workflows, model routing beats model loyalty. Claude Sonnet 4.7 is my default for policy-heavy CRM tasks. GPT-5.5 is my default for broader agent planning, dynamic decomposition, and structured output pipelines. Agentforce 2.0 makes this more realistic because custom reasoning steps, multi-agent orchestration, Data Cloud vector search, and Apex actions give us places to route intelligently.
My Short Answer
If I had to choose one default model for a Salesforce service agent today, I would start with claude-sonnet-4-7.
If I had to choose one model for a multi-step revenue operations agent that has to plan, transform data, write summaries, inspect JSON payloads, and coordinate several tools, I would start with gpt-5.5.
That does not mean one is “better.” It means their failure modes are different.
Claude Sonnet 4.7 tends to be very strong when I need:
- Strict adherence to instructions
- Careful tone in customer-facing drafts
- Better resistance to jumping ahead without evidence
- Strong handling of long policy and knowledge context
- Conservative behavior around approvals and escalations
GPT-5.5 tends to be very strong when I need:
- Multi-step planning
- Structured JSON responses
- Tool coordination across heterogeneous APIs
- Fast iteration in agentic workflows
- Better general-purpose transformation and synthesis
In Salesforce terms: Claude is the teammate I trust with a regulated service case. GPT-5.5 is the teammate I trust with messy orchestration.
The Salesforce Agent Use Cases I Actually Compare
I do not benchmark models by asking riddles. I benchmark them against Salesforce work.
Here are the scenarios I use:
| Salesforce agent scenario | My preferred default |
|---|---|
| Service case triage with strict escalation rules | Claude Sonnet 4.7 |
| Customer email draft from Case + Knowledge | Claude Sonnet 4.7 |
| Sales call summary to Opportunity fields | GPT-5.5 |
| Lead enrichment workflow with external APIs | GPT-5.5 |
| Agentforce 2.0 multi-agent orchestration | GPT-5.5 or routed |
| Data Cloud vector search answer synthesis | Claude Sonnet 4.7 |
| Admin assistant generating Flow/Apex guidance | Claude Sonnet 4.7 |
| JSON transformation for middleware | GPT-5.5 |
| Compliance-heavy approval recommendation | Claude Sonnet 4.7 |
| Dynamic tool planning across Salesforce + ERP | GPT-5.5 |
The distinction matters because Salesforce agents are not chatbots. They are workflow participants. They touch Cases, Opportunities, Knowledge, Entitlements, Orders, CPQ data, ERP records, and customer communications. Bad output is not just embarrassing. It creates operational debt.
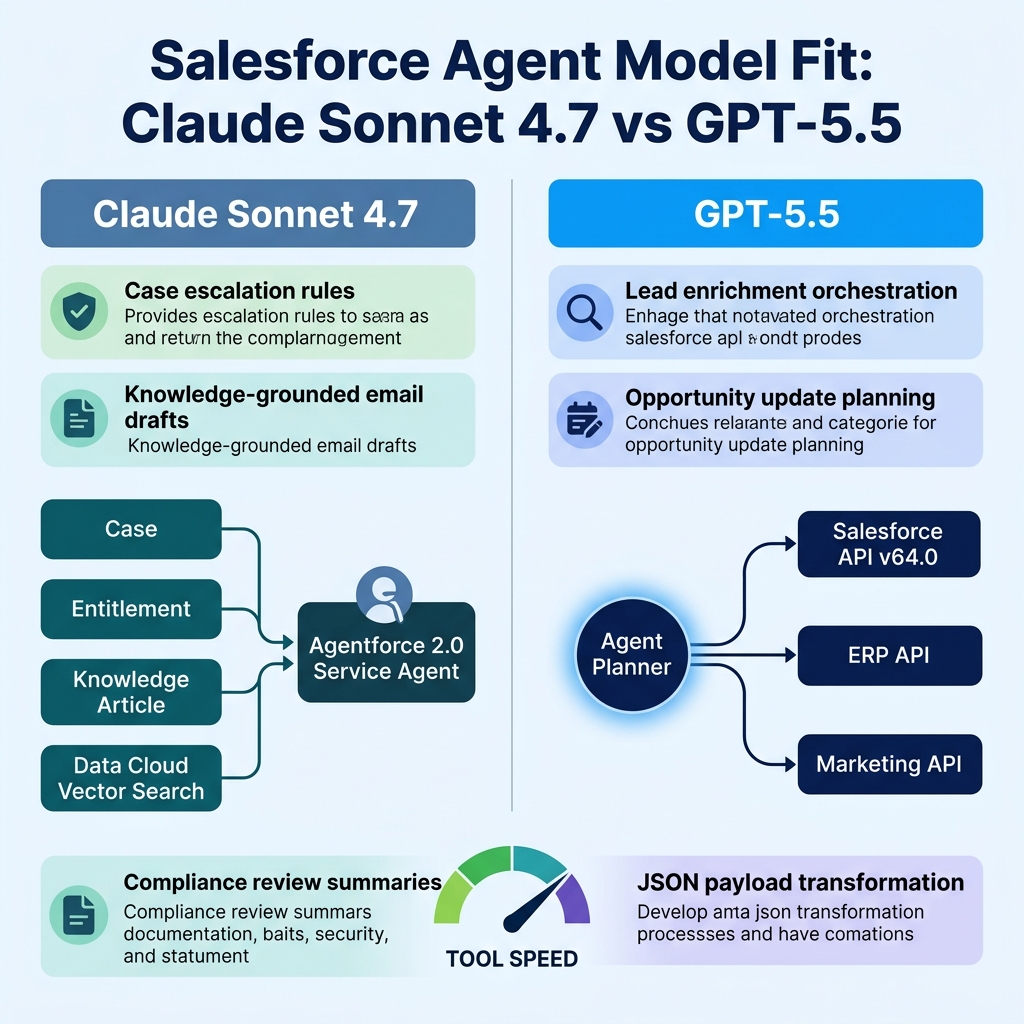
Where Claude Sonnet 4.7 Wins for Salesforce
Claude Sonnet 4.7 is my first pick when the Salesforce workflow has high policy density.
A good example is service escalation.
In one enterprise implementation, we had a support process where escalation depended on:
- Account tier
- Entitlement status
- Case age
- Product family
- Region-specific SLA rules
- Whether the customer had an open Severity 1 incident
- Contract language stored outside the Case
- Internal support notes that could not be exposed to the customer
The agent’s job was not to “be creative.” The agent had to read context, apply rules, explain the recommendation, and avoid exposing internal-only details.
Claude Sonnet 4.7 performed better in this pattern because it was more conservative. It was less likely to overstate confidence. It followed “do not mention internal notes” instructions more reliably. It was also better at producing a response that sounded like a senior support lead instead of a generic chatbot.
That matters.
A Salesforce agent that gives a customer-facing answer needs a different personality than an internal planning agent. I want the customer-facing model to be cautious, grounded, and boring. Boring is good when the workflow can trigger an escalation, refund, RMA, or executive alert.
Where GPT-5.5 Wins for Salesforce
GPT-5.5 is excellent when the agent needs to coordinate a larger workflow.
For example, I used a pattern like this for a revenue operations assistant:
- Read an Opportunity and related Account.
- Pull recent activity history.
- Check product usage from an external telemetry API.
- Compare renewal risk signals.
- Recommend next steps.
- Draft a follow-up task.
- Return structured JSON for Salesforce update actions.
GPT-5.5 handled this style of agent planning very well. It was strong at decomposing the workflow and keeping output structured. It also handled messy API payloads better when the external system returned inconsistent field names.
In Agentforce 2.0, this is useful because you can place GPT-5.5 behind a custom reasoning step where the model decides which actions to call, then enforce write operations through Salesforce permissions, Apex validation, and approval checks.
That is the important part: the model should propose; Salesforce should enforce.
Never let the model be the system of record. Salesforce is the system of record. The model is a reasoning layer.
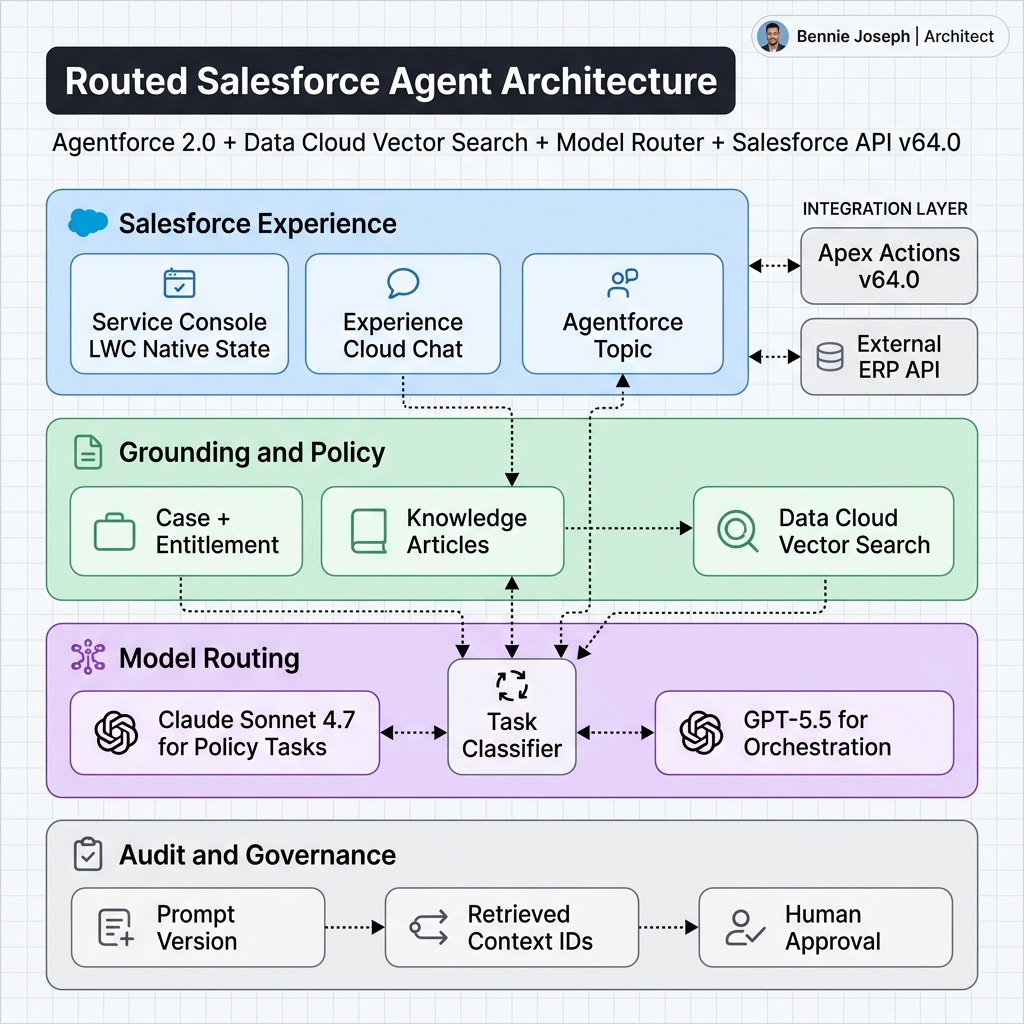
The Architecture I Prefer: Agentforce Plus a Model Router
I rarely wire a Salesforce agent directly to a single model anymore.
My preferred pattern is:
- Agentforce 2.0 handles the user experience, topics, trust layer, and orchestration.
- Salesforce actions and Apex perform governed reads/writes.
- Data Cloud vector search retrieves grounded context.
- A model router chooses Claude Sonnet 4.7 or GPT-5.5 based on task type.
- Audit logs capture prompt, retrieved context IDs, model, response, tool calls, and user action.
This is more work than hardcoding one model. It is also how enterprise systems survive.
Here is a simplified TypeScript example of a model router I would put behind an Agentforce custom action or middleware service. The Salesforce API version is v64.0, the Anthropic API version header is 2026-01-01, and the OpenAI model is gpt-5.5.
type AgentTaskType =
| "CASE_ESCALATION_RECOMMENDATION"
| "CUSTOMER_EMAIL_DRAFT"
| "OPPORTUNITY_RENEWAL_PLAN"
| "LEAD_ENRICHMENT_ORCHESTRATION"
| "JSON_TRANSFORMATION";
type SalesforceAgentRequest = {
taskType: AgentTaskType;
userId: string;
recordId: string;
orgId: string;
prompt: string;
context: {
salesforceApiVersion: "v64.0";
retrievedRecordIds: string[];
dataCloudVectorResultIds?: string[];
policyText?: string;
};
};
type ModelResponse = {
model: "claude-sonnet-4-7" | "gpt-5.5";
content: string;
audit: {
routedBecause: string;
recordId: string;
retrievedRecordIds: string[];
};
};
function chooseModel(req: SalesforceAgentRequest): ModelResponse["model"] {
switch (req.taskType) {
case "CASE_ESCALATION_RECOMMENDATION":
case "CUSTOMER_EMAIL_DRAFT":
return "claude-sonnet-4-7";
case "OPPORTUNITY_RENEWAL_PLAN":
case "LEAD_ENRICHMENT_ORCHESTRATION":
case "JSON_TRANSFORMATION":
return "gpt-5.5";
default:
return "claude-sonnet-4-7";
}
}
export async function runSalesforceAgentTask(
req: SalesforceAgentRequest
): Promise<ModelResponse> {
const model = chooseModel(req);
const systemPrompt = `
You are an enterprise Salesforce agent.
Follow Salesforce sharing, field-level security, and business policy.
Do not invent record values.
Use only provided context.
If a write action is needed, return a recommendation, not a direct mutation.
Salesforce API version: ${req.context.salesforceApiVersion}.
`;
if (model === "claude-sonnet-4-7") {
const response = await fetch("https://api.anthropic.com/v1/messages", {
method: "POST",
headers: {
"content-type": "application/json",
"x-api-key": process.env.ANTHROPIC_API_KEY!,
"anthropic-version": "2026-01-01"
},
body: JSON.stringify({
model: "claude-sonnet-4-7",
max_tokens: 1200,
system: systemPrompt,
messages: [
{
role: "user",
content: JSON.stringify({
taskType: req.taskType,
recordId: req.recordId,
prompt: req.prompt,
context: req.context
})
}
]
})
});
const data = await response.json();
return {
model,
content: data.content?.[0]?.text ?? "",
audit: {
routedBecause: "Policy-heavy Salesforce task requiring conservative reasoning",
recordId: req.recordId,
retrievedRecordIds: req.context.retrievedRecordIds
}
};
}
const response = await fetch("https://api.openai.com/v1/responses", {
method: "POST",
headers: {
"content-type": "application/json",
authorization: `Bearer ${process.env.OPENAI_API_KEY!}`
},
body: JSON.stringify({
model: "gpt-5.5",
input: [
{
role: "system",
content: systemPrompt
},
{
role: "user",
content: JSON.stringify({
taskType: req.taskType,
recordId: req.recordId,
prompt: req.prompt,
context: req.context
})
}
],
text: {
format: {
type: "json_schema",
name: "salesforce_agent_result",
schema: {
type: "object",
additionalProperties: false,
properties: {
summary: { type: "string" },
recommendedActions: {
type: "array",
items: { type: "string" }
},
salesforceUpdates: {
type: "array",
items: {
type: "object",
additionalProperties: false,
properties: {
objectApiName: { type: "string" },
recordId: { type: "string" },
fieldApiName: { type: "string" },
proposedValue: { type: "string" }
},
required: [
"objectApiName",
"recordId",
"fieldApiName",
"proposedValue"
]
}
}
},
required: ["summary", "recommendedActions", "salesforceUpdates"]
}
}
}
})
});
const data = await response.json();
return {
model,
content: data.output_text ?? "",
audit: {
routedBecause: "Orchestration-heavy Salesforce task requiring structured output",
recordId: req.recordId,
retrievedRecordIds: req.context.retrievedRecordIds
}
};
}This is not the whole production design. In production, I add retries, rate-limit handling, tenant-level routing rules, prompt versioning, PII masking, Shield Event Monitoring correlation IDs, and evaluation scores. But the core idea is the same: classify the Salesforce task before choosing the model.
Tool Calling: The Real Differentiator
Tool calling is where Salesforce agents either become useful or dangerous.
I do not care if a model can describe how to update an Opportunity. I care whether it can select the correct governed action, pass the right arguments, and stop when it lacks permission.
For Salesforce, I typically expose tools like:
get_case_summarysearch_knowledge_articlesquery_data_cloud_profilerecommend_escalationdraft_customer_emailpropose_opportunity_updatescreate_follow_up_task_pending_approval
Notice the verbs: get, search, recommend, draft, propose, create pending approval.
I avoid exposing tools like update_opportunity_now directly to the model unless the business case is narrow and heavily controlled. Even then, Apex should enforce CRUD, FLS, sharing, validation rules, and business rules.
Claude Sonnet 4.7 is very good when the tool list is constrained and policy-heavy. GPT-5.5 is very good when the agent needs to chain tools dynamically. Both need guardrails.
Real Enterprise Example: Support Deflection Without Bad Escalations
A real pattern I worked on was support deflection for a B2B SaaS company running Salesforce Service Cloud, Experience Cloud, Knowledge, and Data Cloud.
The business wanted an agent that could answer customer questions, recommend Knowledge articles, and decide when to escalate to a human. The risky part was escalation. If the agent escalated too often, support cost increased. If it failed to escalate, SLA breaches became expensive.
We tested two flows:
Flow A: Single Model
Every request went to one model. It received Case context, Knowledge search results, entitlement data, and the customer message. It returned an answer plus escalation recommendation.
This was simple, but brittle. Some tasks needed careful customer tone. Others needed structured rule evaluation. Others needed retrieval cleanup.
Flow B: Routed Agent
Agentforce 2.0 handled the topic and user session. Data Cloud vector search retrieved relevant Knowledge and contract snippets. A lightweight classifier routed:
- Customer-facing draft → Claude Sonnet 4.7
- Escalation rule explanation → Claude Sonnet 4.7
- Internal JSON payload normalization → GPT-5.5
- Multi-step follow-up plan → GPT-5.5
Flow B was better. Not because either model was magic. It was better because each model got the work it was suited for.
The biggest operational win was auditability. When a support manager asked, “Why did the agent recommend escalation?” we had:
- Case ID
- Entitlement ID
- Knowledge article IDs
- Data Cloud vector result IDs
- Model name
- Prompt version
- Reasoning summary
- Final recommendation
- Human approval status
That is what enterprise AI needs. Not demos. Evidence.
Latency and Cost: Do Not Average the Wrong Thing
Averages lie.
If you average latency across all agent requests, you miss the real user experience. A customer email draft can take a little longer. A service console copilot suggestion during live chat cannot.
For Salesforce agents, I measure latency by interaction type:
| Interaction type | Latency tolerance |
|---|---|
| Live chat suggestion | Low |
| Case summary on page load | Medium |
| Email draft generation | Medium |
| Renewal plan generation | High |
| Overnight account intelligence job | Very high |
Claude Sonnet 4.7 is not always the fastest option. GPT-5.5 is not always the cheapest option. The better approach is to use task-specific budgets.
For lower-cost or high-volume steps, I also consider smaller models:
- claude-haiku-4-7 for lightweight classification
- gpt-5.5-mini for simple transformations
- gemini-3.1-flash for fast utility tasks
- Llama 4 Scout for local/private classification where infrastructure supports it
But for the main comparison in Salesforce agent reasoning, I keep coming back to Claude Sonnet 4.7 and GPT-5.5.
Prompting Differences I Care About
Claude Sonnet 4.7 responds well to explicit policy hierarchy. I give it clear sections:
- Role
- Allowed context
- Forbidden actions
- Escalation rules
- Response format
- Examples
- Refusal behavior
GPT-5.5 responds very well to schemas and task decomposition. I give it:
- Objective
- Available tools
- Planning constraints
- Output schema
- Validation requirements
- Error handling rules
For Salesforce, I almost always include this instruction regardless of model:
Do not assume Salesforce field values. If a field is missing, say it is missing. Do not infer it from customer tone or prior probability.
That one line prevents a surprising amount of garbage.
Security: The Model Is Not Your Control Plane
I see teams make the same mistake: they put too much trust in the prompt.
A prompt is not security. A prompt is guidance.
For Salesforce agents, the control plane must be Salesforce and your middleware:
- Enforce sharing rules.
- Enforce CRUD and FLS.
- Strip fields the user cannot access.
- Mask sensitive values before sending context.
- Use named credentials or secure middleware secrets.
- Log model interactions with correlation IDs.
- Require approval for risky writes.
- Keep prompt templates versioned.
- Test with adversarial examples.
In Apex, I still validate everything. If an LLM proposes an update, I treat it like untrusted user input.
public with sharing class AgentOpportunityUpdateService {
public class ProposedUpdate {
@AuraEnabled public Id recordId;
@AuraEnabled public String fieldApiName;
@AuraEnabled public String proposedValue;
}
@AuraEnabled
public static void applyApprovedUpdates(List<ProposedUpdate> updates) {
if (updates == null || updates.isEmpty()) {
return;
}
if (!Schema.sObjectType.Opportunity.isUpdateable()) {
throw new AuraHandledException('User cannot update Opportunities.');
}
Map<Id, Opportunity> opportunitiesToUpdate = new Map<Id, Opportunity>();
for (ProposedUpdate proposed : updates) {
if (proposed.recordId == null || String.isBlank(proposed.fieldApiName)) {
continue;
}
Opportunity opp = opportunitiesToUpdate.containsKey(proposed.recordId)
? opportunitiesToUpdate.get(proposed.recordId)
: new Opportunity(Id = proposed.recordId);
if (proposed.fieldApiName == 'NextStep') {
if (!Schema.sObjectType.Opportunity.fields.NextStep.isUpdateable()) {
throw new AuraHandledException('User cannot update Next Step.');
}
opp.NextStep = proposed.proposedValue;
} else if (proposed.fieldApiName == 'Description') {
if (!Schema.sObjectType.Opportunity.fields.Description.isUpdateable()) {
throw new AuraHandledException('User cannot update Description.');
}
opp.Description = proposed.proposedValue;
} else {
throw new AuraHandledException('Unsupported AI-proposed field: ' + proposed.fieldApiName);
}
opportunitiesToUpdate.put(proposed.recordId, opp);
}
if (!opportunitiesToUpdate.isEmpty()) {
update opportunitiesToUpdate.values();
}
}
}This is deliberately restrictive. The model does not get to update arbitrary fields because it produced valid JSON. Valid JSON is not valid business intent.
Evaluation: How I Decide Between Them
I use scorecards, not vibes.
For each Salesforce use case, I create 30–100 test cases with expected behaviors. I include normal cases, edge cases, adversarial prompts, missing data, conflicting records, and permission constraints.
My evaluation dimensions:
- Groundedness
- Policy compliance
- Tool argument correctness
- JSON validity
- Refusal correctness
- Tone
- Latency
- Cost
- Recovery from missing context
- Audit usefulness
Then I score Claude Sonnet 4.7 and GPT-5.5 separately by use case.
The winner is rarely universal. For service compliance, Claude often wins. For orchestration and structured transformations, GPT-5.5 often wins. For simple classification, neither flagship model may be necessary.
My Practical Recommendation
If you are starting a Salesforce agent project today, do this:
- Build the agent with Agentforce 2.0 topics and governed Salesforce actions.
- Use Data Cloud vector search for retrieval when answers require enterprise context.
- Start with Claude Sonnet 4.7 for customer-facing and policy-heavy responses.
- Start with GPT-5.5 for multi-tool planning and structured JSON workflows.
- Add a model router before you scale.
- Evaluate against your real Salesforce records, not generic benchmarks.
Do not let procurement, hype, or personal preference pick the model. Let the use case pick the model.
The best Salesforce AI architectures in 2026 are not one-model architectures. They are governed, routed, observable systems where each model is used for the job it is actually good at.
TL;DR
- Use Claude Sonnet 4.7 for Salesforce tasks that require policy discipline, careful tone, and grounded service reasoning.
- Use GPT-5.5 for agent planning, tool orchestration, and structured JSON workflows.
- For serious Agentforce 2.0 implementations, build a model router and let Salesforce enforce security, permissions, and writes.
Salesforce Certified Application Architect · 9+ years · Building AI agents & SaaS products.